
Why Serverless Direct Integrations Aren't As Scary As They Sound
API Gateway direct integrations are shrouded with mystery and doubt. But they shouldn't be. Here's why.


Last week I was on a panel discussion at the Serverless Summit. We were having great discussion talking about app modernization, testing event-driven architectures, and answering questions from the audience.
But one question went by that we didn't have an opportunity to answer. So I wanted to take the time to discuss it because it's been raised to me a few times recently.
The question posed was "are you concerned about testing lambda-less functions and their overall maintainability?"
I saw some hesitation on this concept on Twitter as well when I was talking about building Express Step Function workflows instead of Lambda functions.
The worries that are cropping up from the community aren't surprising to hear. When we talk about new, not widely used patterns like direct integrations with API Gateway people get scared. It's change. People don't like change. Especially developers.
So let's talk about direct integrations, some common concerns, and why they may or may not be a problem.
Components of a Direct Integration
When I say direct integration, I mean connecting a REST API in API Gateway directly to another AWS service without using a Lambda function. There are direct integrations in Step Functions, DynamoDB, SQS, and over a hundred more services.
To connect an API Gateway endpoint to another AWS service like DynamoDB, you make use of VTL and API Gateway mapping templates. VTL is a beast on its own, but layer in the capabilities that are or are not supported by API Gateway and you have a steep learning curve.
Outside of the VTL, you have an IAM role and logs. That's basically it. One of the things that is so appealing to direct integrations is how few moving parts there are.
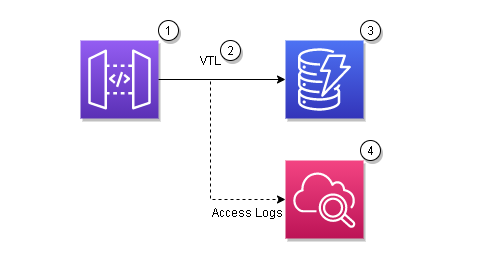
- REST API in API Gateway
- VTL mapping templates
- Directly connected AWS Service
- Execution and access logs in CloudWatch
Compared to an integration with a Lambda function, a direct integration provides you with fewer parts, lower latency, no cold starts, and lower cost.
So what is all the hubbub about?
Concerns with Direct Integrations
Across the many conversations I've had about VTL and direct integrations, there has been a handful of concerns that are always brought up.
VTL Is Hard and Confusing
There's no doubt that VTL leaves something to be desired. I'm not here to argue that case. But what I am here to do is remind you not to confuse complexity with unfamiliarity. If you're unfamiliar with anything (not just VTL) it's going to seem more complicated than it actually is. When I first started with GraphQL, I thought it was insanely complex. But that was just because I hadn't spent the time actually learning it and understanding its nuance.
The same goes for VTL. With practice, you start picking up the detail that makes it sing. You learn how to transform objects, iterate nested arrays, set headers and response codes, and take advantage of the built-in util functionality from AWS.
Yes, this is yet another thing your dev teams will have to learn, but it's quickly becoming an accepted, albeit annoying, part of cloud development. The thought that you can't "hire someone off the street" to come in and maintain a direct integration is quickly becoming untrue.
So give it some practice, review some examples, and embrace it!
Direct Integrations Are Impossible to Debug
The first time I built a direct integration with DynamoDB and got a 502 Bad Gateway response code, I had no idea what to do. I went to go look at the logs, but there were none. I was used to reviewing the CloudWatch logs from a Lambda function, but I couldn't find them for my integration. Pretty much immediately I was out of things to do. It felt like there was nowhere for me to go to troubleshoot.
Little did I know, there are two ways to get unstuck from a situation like this.
The API Gateway console allows you to test endpoints directly and view a detailed response if something went wrong. This can be used for debugging issues with your mapping templates or for identifying any missing permissions from the role your endpoint is using.
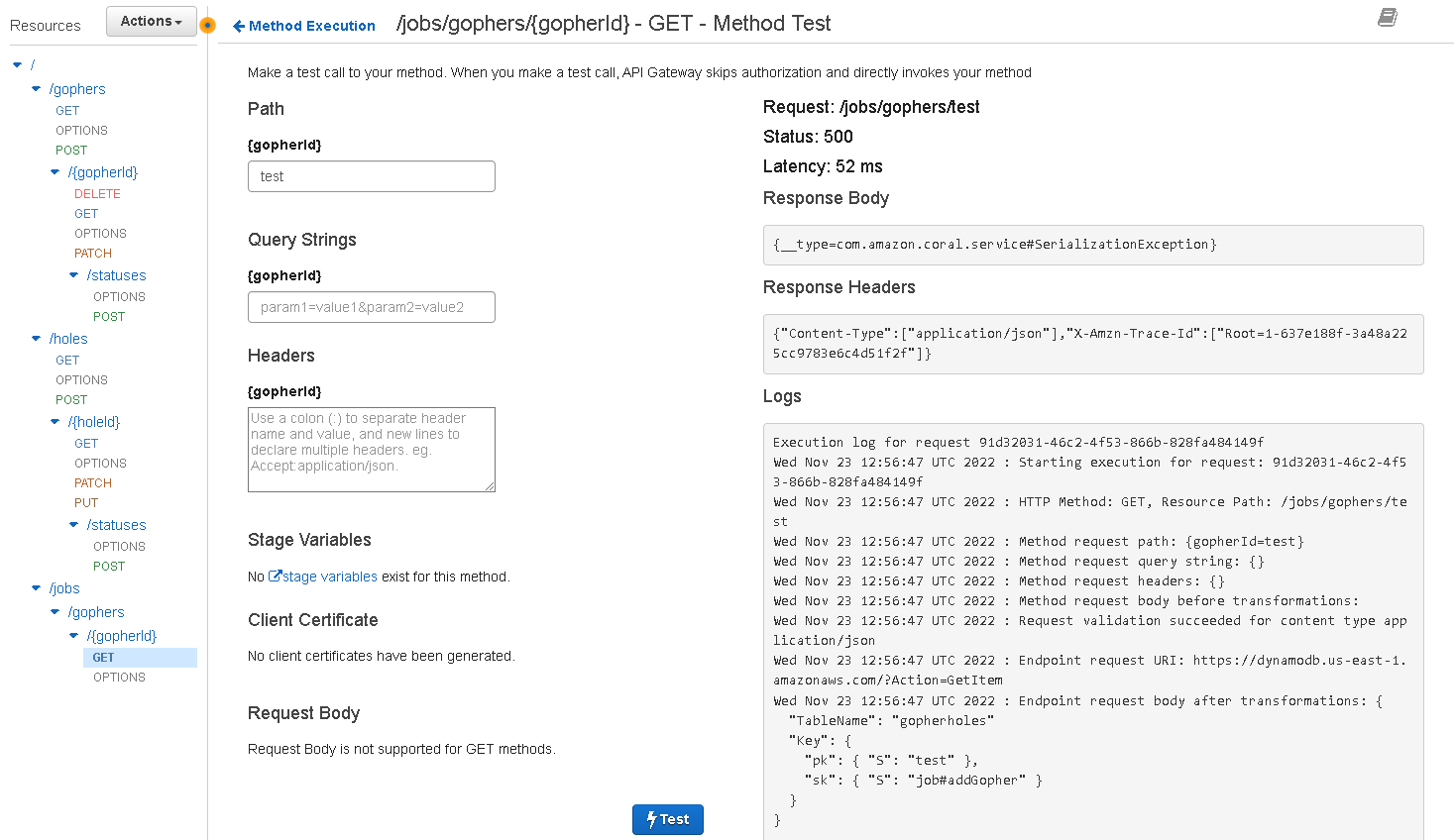
Manually testing in the API Gateway Console
You can also configure execution and access logs on your REST API. These logs not only show you what went wrong, but it also shows you detailed information on who is calling your endpoints. These logs are off by default and are not unique to direct integrations. Depending on how much traffic your API gets, both the access and execution logs of your API could be expensive, which is my speculation why they are off by default.
The API Gateway console will display the execution logs automatically. But once you enable them in your Infrastructure as Code (IaC) these logs will be pushed to CloudWatch and you can support direct integrations in the same way you would with a Lambda function integration, assuming you troubleshoot them by looking at the logs :smile:
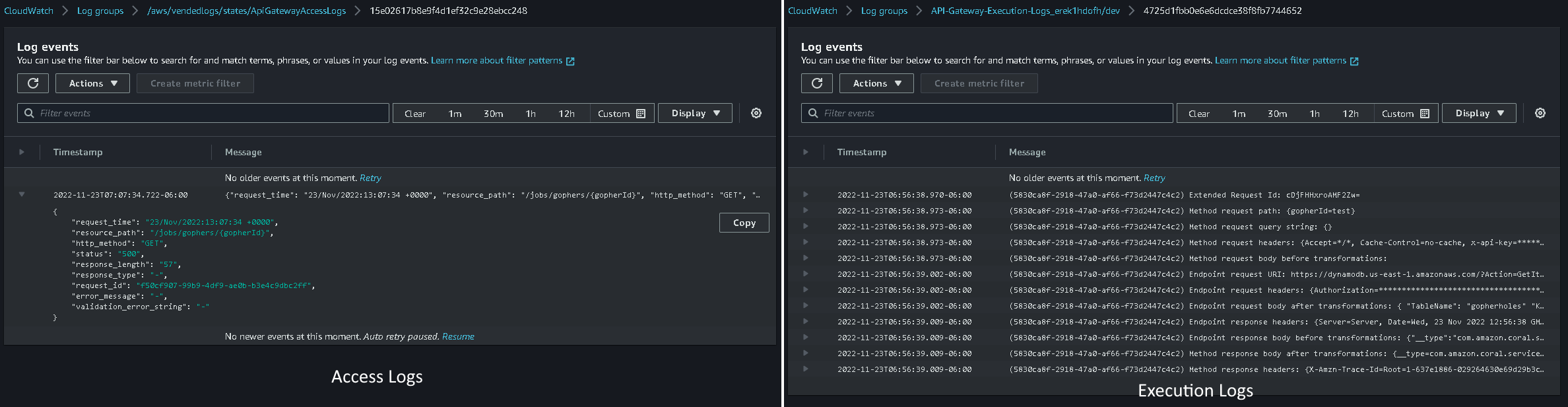
Access and execution logs from API Gateway
Pairing the execution logs with the access logs will give you enough information to debug any issue that arises with your direct integration.
To setup the logs in IaC, you can configure your API resource and setup a log group, role, and API Gateway account.
You Lose A Layer Of Business Validation
I was talking with Alex Debrie the other day about direct integrations and he brought up a good point. When you're directly connecting to services like DynamoDB, you lose a layer of business rules and validation that you'd otherwise normally get in a Lambda function.
Unsurprisingly, Alex is a smart man and brings up a valid concern. 99.9% of the time business rules are implemented as logic inside of your code, so you miss out on this when directly integrating. But it's not as black and white as it might seem on the surface.
API Gateway provides robust schema validation for requests coming into your API. You can define the request body in JSON schema draft 4 and API Gateway will ensure the message payload adheres to the schema. If it does not, the request is blocked and does not make it to your integration.
While this is not a code-driven business rule engine, it does offer a layer of validation that satisfies many use cases.
If you need validation beyond basic message structure, your options are limited. If you're directly integrating to something like DynamoDB and you need a layer of business logic prior to a save or update, a Lambda function is the way to go.
But if you're integrating with Step Functions, you can add business logic as states in your state machine.
You Cannot Unit Test Them
Unit tests are at the bottom of the testing pyramid. They are intended to validate that your code does what you expect it to do. But with direct integrations, there is no code - it's all configuration! So do you really need to test it?

Yes. Yes you do need to test it.
But in this case we're going to shift up our tests. Rather than rely on something like unit tests to validate our code, we're relying on integration tests. These tests run against the actual implementation of our code, rather than locally testing them (hence the shift up mentality).
You can run fuzzy tests against your endpoints to test every permutation of your requests. This will exhaustively test your direct integration and ensure you get the response you intend no matter the provided payload.
Having a strong set of tests and a rollback mechanism is crucial to your success with direct integrations. Since you rely on the integration to be deployed in order to effectively test it, being able to rollback if something goes wrong is a must-have.
So while you may not be able to unit test locally, they are a testable resource. You won't be pushing anything untested into production!
Conclusion
Like many things we've seen with serverless, incorporating direct integrations into your application is a bit of a mindset shift.
You're learning a new language (VTL), parsing through a different set of logs, relying on schema validation for your business layer, and shifting your testing mechanisms up into the cloud.
Honestly, I see why it's scary. There is a surprising amount of extra work and consideration when attempting to remove infrastructure.
For some, it might not be worth the investment to upskill the dev teams to support something new. Teaching developers VTL and how direct integrations flow is an ongoing cost during the maintenance cycle of your application, which adds to your total cost of ownership.
The tradeoff for the new skills is fewer resources to manage, faster response times, lower monthly bill, and less resource contention on service limits like concurrent Lambda function executions.
It's not just about the initial build, it's about longevity of your solution in the long run. Like Lee Gilmore suggested in his tweet, will it disrupt your organization too much to add another mechanism to build and debug? How willing is your business to invest in the engineers that keep your application running?
There are several decisions that drive the effectiveness of direct integrations that extend beyond "how easy is it for developers to build". Organizational concerns are in play that may weigh on the decision to do something new.
It's up to solutions architects to educate and inform on the effectiveness of new solutions and the benefits of patterns like direct integrations.
Ultimately the choice is yours. We've found great success with them on my team, and I hope you do with yours as well.
Happy coding!